Analog Feed Forward Neural Networks
Daniel J. B. ClarkeGilart Hasse School of
Computer Sciences & Engineering
Fairleigh Dickinson University


Motivation

Neural network applications in Machine Learning
Nueral Networks
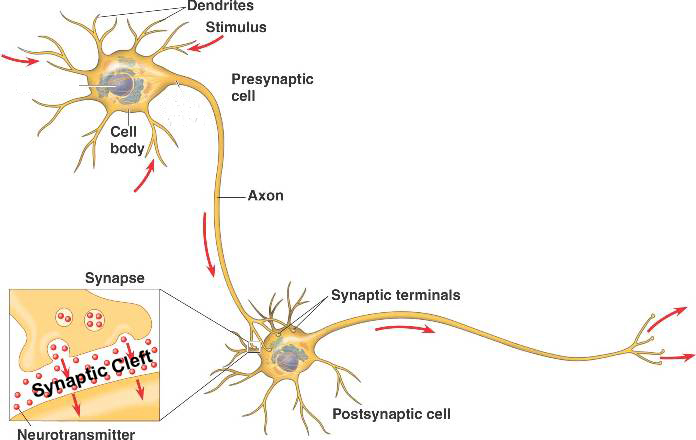
A model of the biologic brain
Current Approach


Objective
Build an Analog Feed Forward Neural Network
- Test on AND, OR, XOR
- Benchmark against software-based implementations
Theory
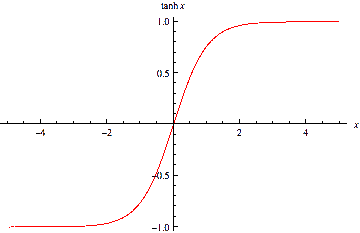
$$y_j=\tanh\left(\sum_i^n{x_{ji}w_{ji}}\right)$$
Learning
$$\Delta w_i=\underbrace{\alpha}_\text{Learning Rate}\underbrace{(\overbrace{t_i}^\text{Target}-\overbrace{y_i}^\text{Output})}_\text{Error}\times \underbrace{x_i}_\text{Input}$$
Theoretical Simulation
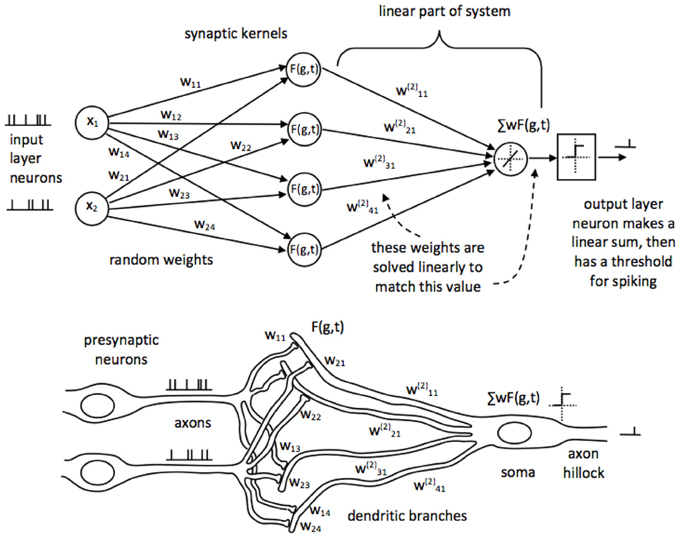
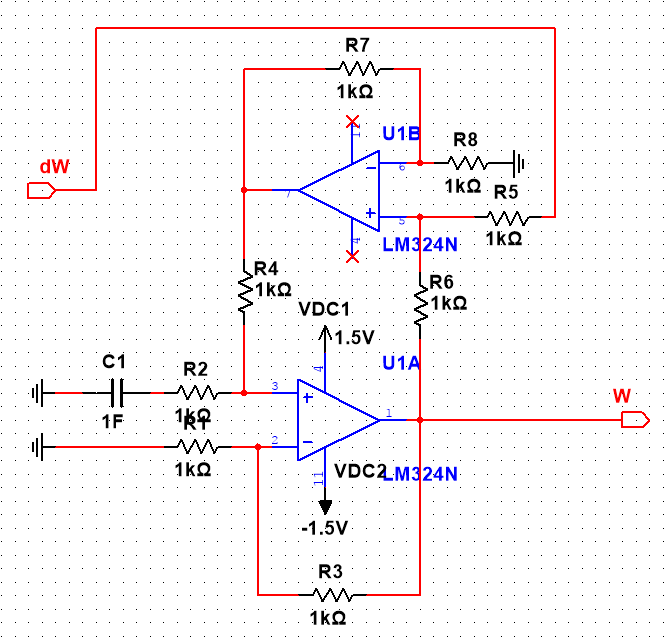
Design & Simulation
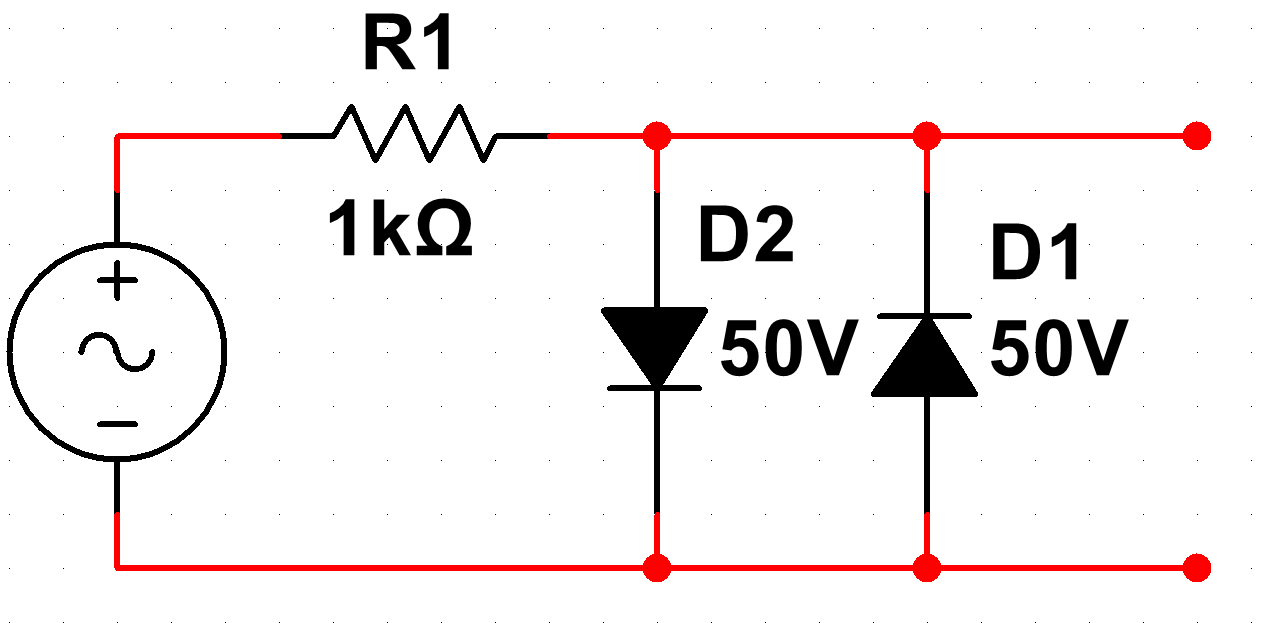
$$y_j=\overbrace{\tanh}\left(\sum_i^n{x_{ji}\times w_{ji}}\right)$$
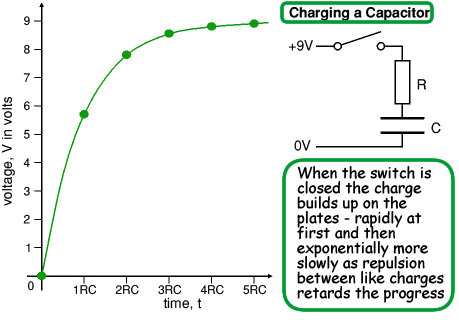
$$\Delta w_i=\overbrace{\alpha}(t\overbrace{-}y_i)\times x_i$$
$$\overbrace{\Delta w_i}=\alpha(t-y_i)\times x_i$$
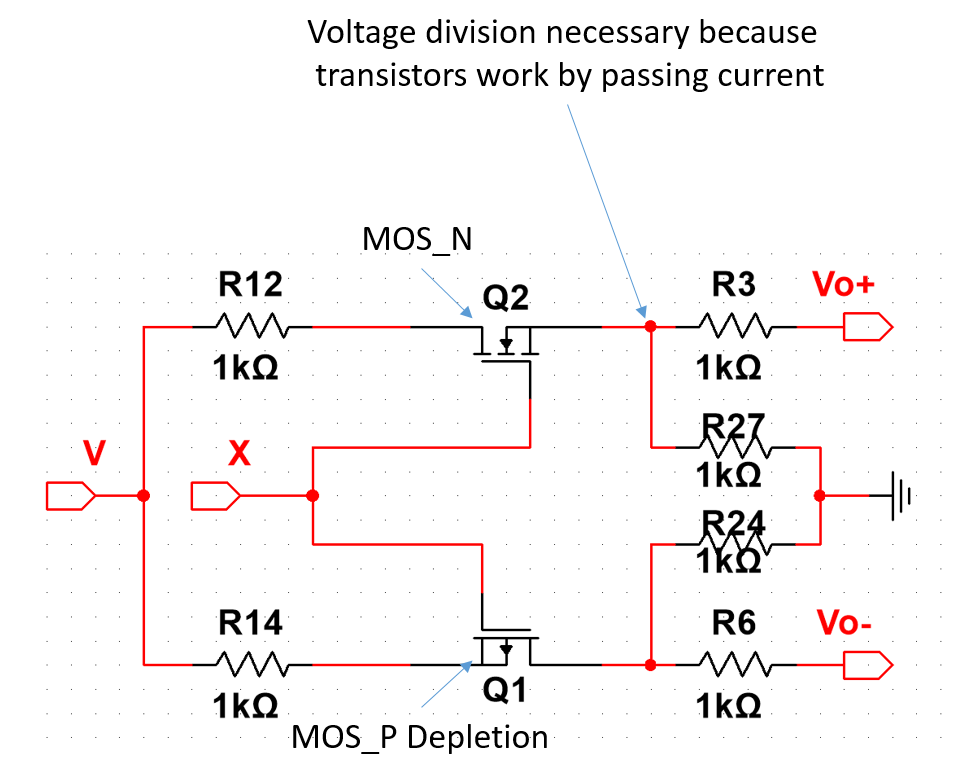
$$\Delta w_i=\alpha(t-y_i)\overbrace{\times} x_i$$
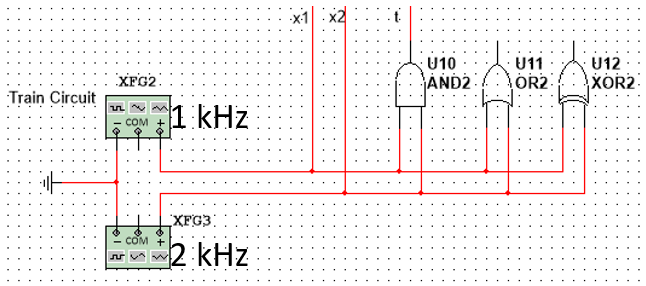
$$\Delta w_i=\alpha(\overbrace{t}-y_i)\times \overbrace{x_i}$$
Complete
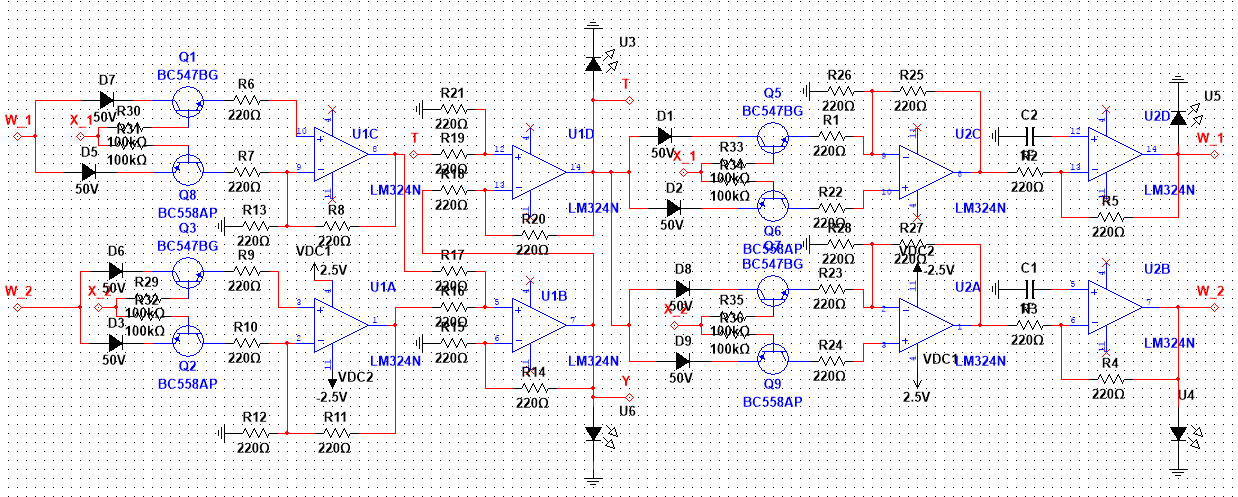

Circuit in action
Results
| Software | Hardware* | ||||
| Test | Time (ms) | Learned | Epochs | Time (ms) | Learned |
|---|---|---|---|---|---|
| AND | 0.51 | True | 10 | 0.022 | True |
| OR | 0.42 | True | 12 | 0.026 | True |
| XOR** | 4.62 | False | - | - | False |
* These results are theoretical based on RC constant. ** This result is expected, a 2-1 FFNN is required for XOR.
Conclusion
-
Realization of Analog Feed Forward Neural Network
- Hardware accelerated machine learning driven by software
- Inherent scalability
References
- P. Auer, H. Burgsteiner, and W. Maass, “A learning rule for very simple universal approximators consisting of a single layer of perceptrons,” Neural Networks, vol. 21, no. 5, pp. 786 – 795, 2008.
- H. P. Graf and L. D. Jackel, “Analog electronic neural network circuits,” IEEE Circuits and Devices Magazine, vol. 5, pp. 44–49, July 1989.
- M. Ueda, Y. Nishitani, Y. Kaneko, and A. Omote, “Back- propagation operation for analog neural network hardware with synapse components having hysteresis characteris- tics,” PLOS ONE, vol. 9, pp. 1–10, November 2014.
- M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V. Vasudevan, P. Warden, M. Wicke, Y. Yu, and X. Zheng, “Tensorflow: A system for large-scale machine learning,” in Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, OSDI’16, (Berkeley, CA, USA), pp. 265– 283, USENIX Association, 2016.
- E. Rosenthal, S. Greshnikov, D. Soudry, and S. Kvatinsky, “A fully analog memristor-based neural network with online gradient training,” in 2016 IEEE International Sym- posium on Circuits and Systems (ISCAS), pp. 1394–1397, May 2016.
Thank you
Contact: danieljbclarke@gmail.com